Building A Search Engine From Scratch
2022
For a uni course project, we built a search engine, and this ended up being one of the most interesting projects I’ve worked on so far. We ended up building a system that searches 23 million scientific papers in less than 0.25 seconds, essentially bootstrapping our own mini-Google Scholar.
We experimented with a few retrieval algorithms side by side: TF-IDF, BM25, and a transformer-based vector search. The whole system sits on a single MongoDB instance on GCP. Just a very inefficient database that was never designed for a search engine, but with some work, we made it behave like one.
The database problem
To get started, we built a large corpus using many open-source archives such as ArXiv and PubMed. We tokenised these to build a lexicon of 5 million distinct terms stored in an inverted index.
An inverted index is the core data structure behind keyword search. Instead of mapping documents to the words they contain (like a book), it flips the relationship: it maps every word to the list of documents that contain it, along with where in each document it appears. Since we had semi-structured data from different sources, we chose MongoDB for its JSON-like schemas, but we had to deal with MongoDB’s 16 MB record size limit. For most data, you never really hit this. But for us, terms like “research,” “result,” and “method” appeared in over 40% of the documents. So, a single postings list for one of these terms blows past 16 MB easily.
We solved this with bucket overflow with chaining — a classic database pattern, but we had to implement it ourselves at the application layer since MongoDB doesn’t handle this for you. To build this, we gave each term a primary bucket capped at 200,000 postings entries. When that fills up, a new overflow bucket is created and linked from the primary via a chain array.
┌──────────────────────────────────────────┐
│ PRIMARY BUCKET │
│ term: "imag" │
│ doc_count: 842,000 │
│ chain: [overflow_1, overflow_2] │
│ docs: [ {id, freq, pos}, ... (200k) ] │
└──────────────────┬───────────────────────┘
│
┌────────────┴────────────┐
▼ ▼
┌──────────────┐ ┌──────────────┐
│ OVERFLOW 1 │ │ OVERFLOW 2 │
│ docs (200k) │ │ docs (200k) │
└──────────────┘ └──────────────┘Figure 2: Bucket overflow with chaining. Each bucket holds at most 200K entries. Overflow spills into linked buckets.
This split the sorted postings list across multiple buckets, but we couldn’t just load and merge, as some terms had millions of entries. To resolve queries without loading millions of entries into application memory, we offloaded the array fetching to MongoDB using custom aggregation pipelines to resolve the document chains, performing fast bitset operations on the node to keep multi-term lookups under a second.
Ranking algorithms
With the inverted index working, we needed a way to rank what came out of it. We tried two simple approaches first: TF-IDF and BM25.
TF-IDF is the simplest search algorithm that scores documents by how often they contain the query terms (term frequency), weighted against how rare those terms are globally. A document with “quantum” mentioned 15 times beats another that only has it 2 times.
BM25 is supposed to be the upgrade on TF-IDF. It adds a saturation curve so the 100th occurrence of a word contributes less than the 10th, and it explicitly normalizes for document length to handle length variation better. In theory. But it actually performed worse on our evals. BM25’s length normalisation hurt more than it helped. Cosine TF-IDF hit 40% satisfaction versus BM25’s 22%, measured as relevant docs in the top 10 across 100+ queries. Nearly 2x difference.
Both these methods have the same fundamental ceiling: they only match keywords and have no semantic awareness. So a search for “machine learning applications in healthcare” won’t find a paper titled “Neural network diagnostics for clinical imaging.” Even if it’s a very relevant paper. So, we used a vector based search to build this.
Vector search with ScaNN
We used a Sentence Transformer, a distilled model trained on 1 billion+ sentences, to map every document’s title and abstract into an N-dimensional vector. Unlike TF-IDF, the transformer produces contextualembeddings. A word like “bank” gets a different vector depending on whether the surrounding text is about finance or rivers. Distance between points = semantic similarity. “machine learning in healthcare” ends up close to “neural network clinical diagnostics”, even with zero keyword overlap.
But the catch with this is it’s hard to scale. Answering a single query means computing similarity score against all 23 million vectors, the fundamental problem with every nearest neighbor algorithm. To deal with this, we used Google’s ScaNN method. ScaNN outperforms every other ANN library with roughly 2x throughput at the same accuracy. This is due to anisotropic vector quantization.
Most ANN algorithms compress database vectors so that approximate similarity scores are cheaper to compute. This is typically done by learning a codebook of representative vectors and snapping each embedding to its nearest entry, minimizing reconstruction error. ScaNN’s insight is that reconstruction fidelity doesn’t matter uniformly. Quantization error parallel to the original vector directly corrupts similarity score estimates, while orthogonal error barely affects them. ScaNN penalizes parallel error far more heavily, deliberately accepting worse overall reconstruction to get sharper estimates on high-relevance candidates — more aggressive compression, faster search, without degrading top-K quality.
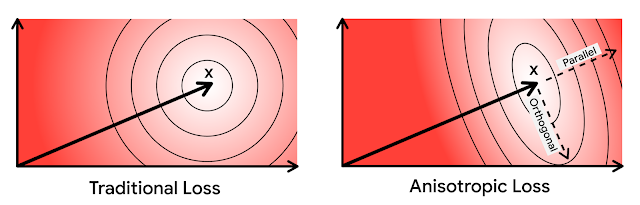
Here ellipses denote contours of equal loss. In anisotropic vector quantization, error parallel to the original data point x is penalized more.
This approach helped our vector search hit 38% ranking satisfaction on our evals, close to TF-IDF’s 40%, but totally dominated on long natural-language queries where keyword methods fall apart.
Wrapping up
We spent three months working on this. Way too much time on what was meant to be a simple course project. But it turned into one of the more interesting things I’ve worked on this year. From scraping data and fighting MongoDB’s document limits, to researching vector quantization techniques. We built a system that searches millions of documents and managed to make three fundamentally different retrieval paradigms coexist on a single MongoDB instance that was never designed for it.